Doubling experiment with worst-case time complexity analysis
Overview
This article goes over the tool created by Team Four of the Algorithm Analysis class, which analyzes the worst-case time complexity of a sorting function.
Project can be found here: https://github.com/boulais01/all-hands-sorting-analysis-4/tree/main
Project Purpose
Bellow the is output from running different commands in a (linux) terminal. The commands are explained in depth bellow the sections of terminal output.
poetry run de --filename tests/benchmarkable_functions.py --funcname bubble_sort
Benchmarking Tool for Sorting Algorithms
Filepath: tests/benchmarkable_functions.py Function: bubble_sort Data to sort:
ints Number of runs: 5
Minimum execution time: 0.0010673040 seconds for run 1 with size 100 Maximum
execution time: 0.2696081410 seconds for run 5 with size 1600 Average
execution time: 0.0721370716 seconds across runs 1 through 5 Average doubling
ratio: 3.9996190149 across runs 1 through 5
Estimated time complexity for tests/benchmarkable_functions.py -> bubble_sort:
O(n²)poetry run de
Benchmarking Tool for Sorting Algorithms
Estimated time complexity for tests/benchmarkable_functions.py -> bubble_sort:
O(n²)
Estimated time complexity for tests/benchmarkable_functions.py ->
bubble_sort_str: O(n²)
Estimated time complexity for tests/benchmarkable_functions.py ->
selection_sort: O(n²)
Estimated time complexity for tests/benchmarkable_functions.py ->
insertion_sort: O(n²)
Estimated time complexity for tests/benchmarkable_functions.py -> heap_sort:
O(n log(n))
Estimated time complexity for tests/benchmarkable_functions.py -> quick_sort:
O(n log(n))
Estimated time complexity for tests/benchmarkable_functions.py -> merge_sort:
O(n log(n))Our program has commands to show the user both the empirical analysis and the theoretical analysis of running the six functions in the benchmakarble_functions.py file.
poetry run de --filename tests/benchmarkable_functions.py --funcname bubble_sort is the command that returns empirical results. This command performs a doubling experiment similar to that of Algorithm Analysis Project 4. However, one difference is that our tool will only print the minimum, maximum, and average run times. For this example this command calls the file benchmakarble_functions.py which contains six different sorting functions. We have tested the different functions and have recorded the expected Big O notation based on analysis of the code. Therefore, as we test our empirical results, they should confirm the expected Big O notation. The last element of the command line is the function name, which determines what function in the file will run. This command shows the running time/empirical results of running different functions in a certain file which for this example is the function bubble_sort in the file benchmakarble_functions.py. This baseline file, is just a baseline. We are using it to test our program, and it is expected that a user will create their own file to pass ink through the command line call.
In addition to showing the user empirical results, our product also gives the user options to display the run time results from running all the commands in benchmakarble_functions.py. The computer calculates the possible Big O notation based on the empirical results. However, a point to note is that this means the Big O notation is not always completely accurate. Sometimes the empirical results change when, for example, different factors of the computer’s environment change. Then the ratio will not exactly represent the expected ratio for certain Big O notations, though it will be very close. The command to show the empirical results is poetry run de. This command will run all the function in the benchmakarble_functions.py file and in the terminal prints the possible Big O notation for each function. Our product gives the user multiple options in the output and result they would like to see and analyze.
Project Code
This project allows for the user to input a file name, function name, data type, start size, and number of runs. If the user does not supply any arguments, the running time of six sample algorithms are tested and reported. An example of the default program being run is in the following code block:
$ de
Benchmarking Tool for Sorting Algorithms
Estimated time complexity for tests/benchmarkable_functions.py -> bubble_sort: O(n²)
Estimated time complexity for tests/benchmarkable_functions.py -> bubble_sort_str: O(n²)
Estimated time complexity for tests/benchmarkable_functions.py -> selection_sort: O(n²)
Estimated time complexity for tests/benchmarkable_functions.py -> insertion_sort: O(n²)
Estimated time complexity for tests/benchmarkable_functions.py -> heap_sort: O(n)
Estimated time complexity for tests/benchmarkable_functions.py -> quick_sort: O(n log(n))
Estimated time complexity for tests/benchmarkable_functions.py -> merge_sort: O(n log(n))It is worth noting that there is sometimes variance in the results, so multiple runs may produce slight variations.
Dynamically Loading Python Files
In order for de to dynamically load Python files, we make use of python’s compile and exec functions:
# path.py
# ...
with open(filename, 'r') as file:
code = compile(file.read(), filename, 'exec')
namespace = {}
exec(code, namespace)
if funcname not in namespace:
raise AttributeError(f"Function '{funcname}' not found in '{filename}'")
if not callable(namespace[funcname]):
raise BalueError(f"'{funcname}' was not found to be a function.")
# ...This code loads the symbols from filename into the AST, making the funcname available under the current namespace. The function’s parameters are then counted to determine if the function only needs a list as input or if it needs a list and the list length.
Generating Input Data
de has the ability to generate random input data for ints, floats, and strings. In general, each generation procedure creates a list of a specified size with randomly-populated input data.
Benchmarking Sorting Algorithms
To benchmark the sorting algorithms, de exercises the use of a doubling experiment to double the size of input data for each run. Each run uses the time.perf_counter method to measure the execution time of running functions, as seen in the following code:
# benchmark.py
# ...
start = time.perf_counter()
funcname(list_one)
stop = time.perf_counter()
times_list.append((i + 1, size, stop - start))
# ...In this case, funcname is a Callable. After timing the function’s execution, we append its result to the list of data, which is used to analyze results.
Analyzing Benchmark Results
To analyze the benchmarking results, we calculate the average doubling ratio between runs. This is done in the following code:
def compute_average_doubling_ratio(times_list: List[Tuple[int, int, float]]) -> float:
times = [item[2] for item in times_list]
# iterate through times, calculating doubling ratios between runs
doubling_ratios = [times[i+1] / times[i] for i in range(len(times) - 1)]
# calculate average doubling ratio
return sum(doubling_ratios) / len(doubling_ratios)By calculating the average ratio between execution times in our doubling experiment, we can develop an approximation of the worst-case time complexity of the sorting algorithms we are testing.
After computing the average doubling ratio, we make a conjecture of the worst-case time complexity based on the doubling ratio, as seen in the following image:
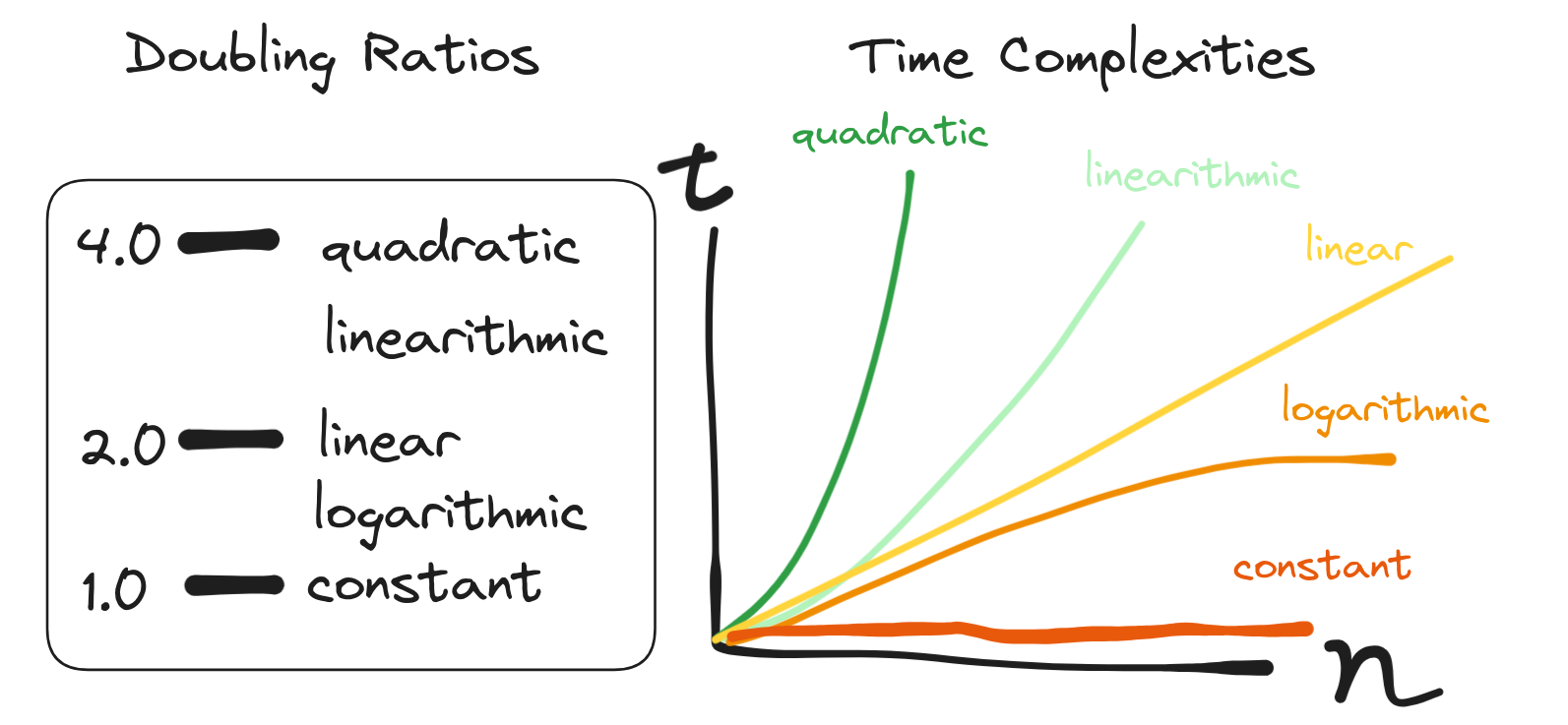
Doubling Ratios
As established in prior sections, the tool discussed here presents the estimated worst-case time complexities of the sorting functions passed in. The above section outlines the calculation of the doubling ratio in particular, which is the primary value in calculating the worst-case time complexity.
The tool uses six values to describe the worst case time complexity, which are as follows:
constant = "1"
linear = "n"
quadratic = "n²"
logarithmic = "log(n)"
linearithmic = "n log(n)"
notsure = "not sure"These are common worst-case time complexities, with an option for if the doubling ratio is not one of these accounted for. They are shown using O(n) notation, and are those that are included in the output after the doubling ratio is run and processed.
Below is an example of the code which processes the doubling ratios.
def estimate_time_complexity(average_doubling_ratio: float) -> enumerations.TimeComplexity:
"""Estimate the time complexity given the average doubling ratio."""
average_doubling_ratio_rounded = round(average_doubling_ratio)
if average_doubling_ratio >= 1.75 and average_doubling_ratio <= 2.25:
return enumerations.TimeComplexity.linear
elif average_doubling_ratio > 2.25 and average_doubling_ratio < 3.75:
return enumerations.TimeComplexity.linearithmic
elif average_doubling_ratio >= 3.75 and average_doubling_ratio_rounded <= 4.25:
return enumerations.TimeComplexity.quadratic
elif average_doubling_ratio > 1.25 and average_doubling_ratio < 1.75:
return enumerations.TimeComplexity.logarithmic
elif average_doubling_ratio_rounded == 1:
return enumerations.TimeComplexity.constant
# indicate that it does not match any of our predefined values
else:
return enumerations.TimeComplexity.notsureThis function, estimate_time_complexity, takes in the average doubling ratio calculated from the benchmarking data, and assesses where it falls in these ranges to determine if it is equivalent to that of one of the time complexity defaults defined previously, and if not, returns the enum representing that it is outside the tool’s scope of comprehension.
Thus, by examining the ratio of the increase in time, the tool can estimate which, if any, known base case of worst-case time complexity the sorting function has.
Conclusion
The code gives us a clear understanding of what is the worst-case time complexity for each function in the code. The creation of this leads to a clear understanding of the code of finding a path and reading a generated input and processing the data and displaying the worst case time complexity. The analysis of the code allows us to be able to calculate the average and furthermore examine roughly the worst-case time complexity. Each component of the code reads and understands the next as it processes the function and gives results showing how the code has it’s worst case time complexities as well as what the worst case time complexity is.